

This post is for myself to remember how to Scrape/Crawl using Beautiful Soup.
The video SUB) Crawling text and images with Python from JoCoding (in Korean) and Beautiful Soup Documentation are the main reference.
I am doing this on Linux Ubuntu 20.04.4 LTS. Using Pycharm Community Edition.
1. Setup the environment
- open Pycharm Community Edition
- Create New Project, using Pycharm is good because you don’t have to do install/activate virtual environment every time you run the project.
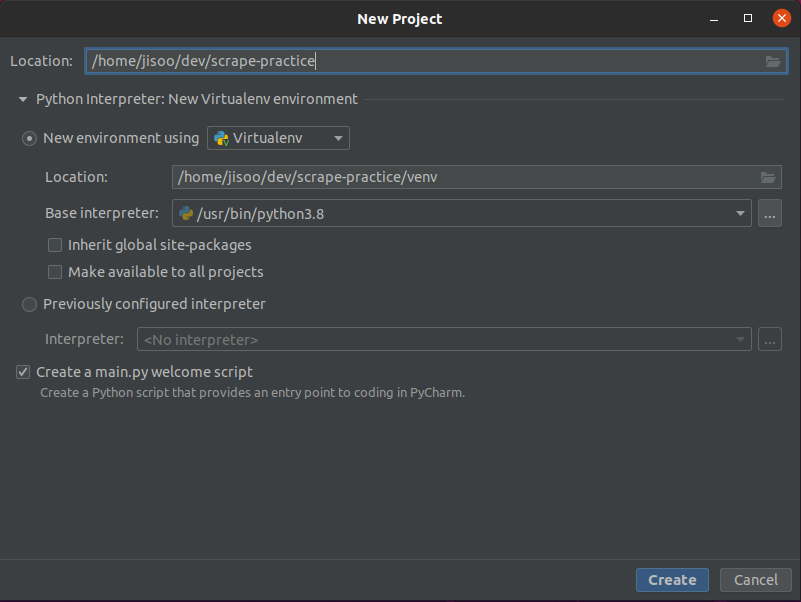
- If you want to create Git repository to track changes, there is version control on your bottom left corner(probably).
- if you want to share/push your project to your github, Git -> Github -> Share Project on Github
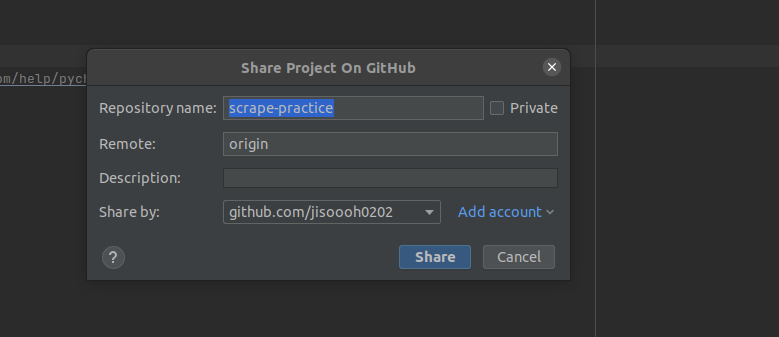
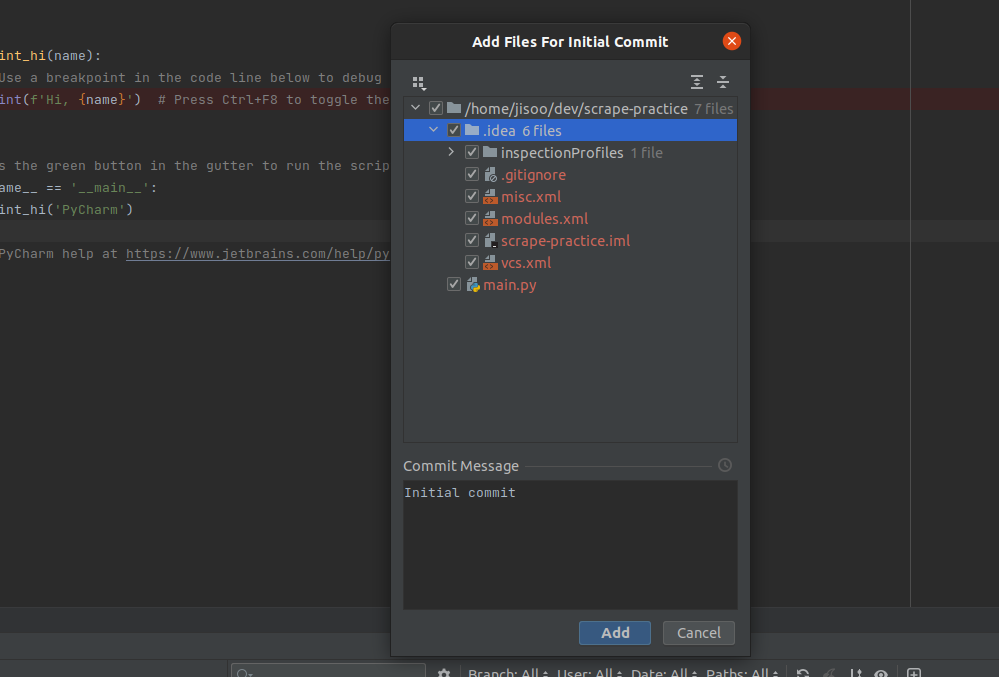
- you can uncheck whatever you don’t want to push. Usually, people do not push .idea folder, I guess….
- click add button to commit.
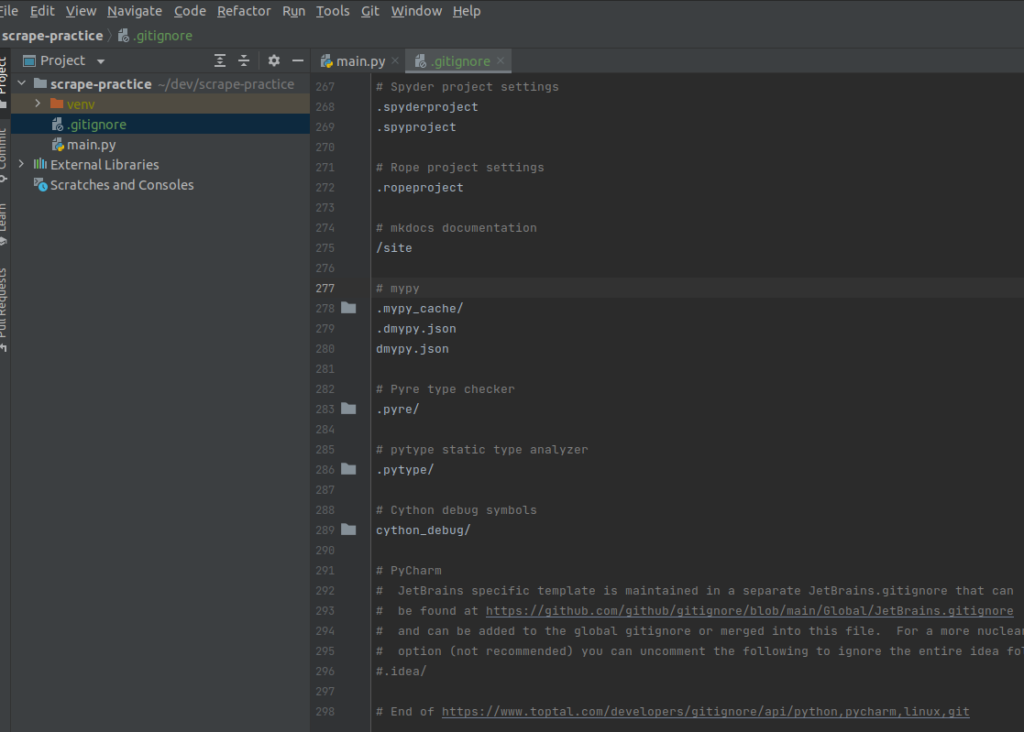
- create .gitignore file under the root project folder. (there is one in venv/.idea folder, but better(or required?) to have one in root project folder.
- https://www.toptal.com/developers/gitignore go to this site and create one for your gitignore
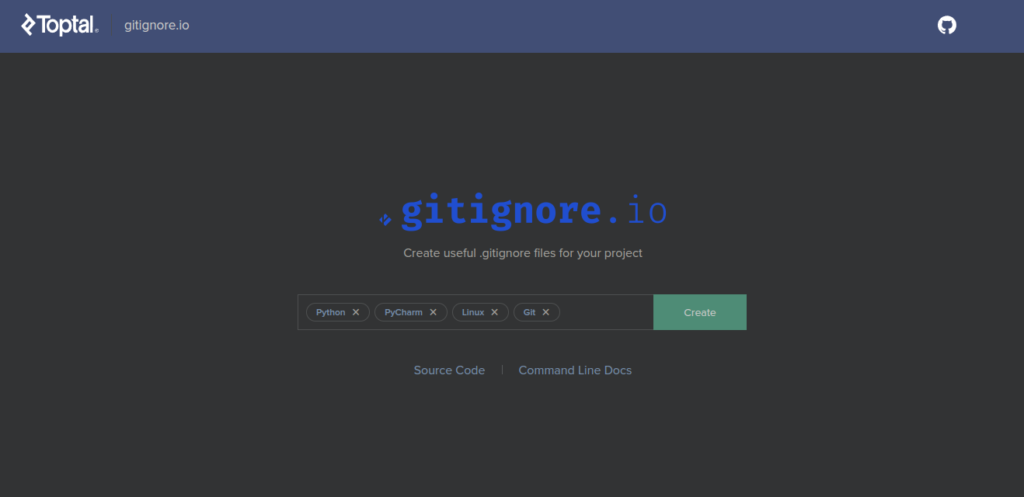
- copy the result and paste in .gitignore file just created.
2. install BeautifulSoup and sample test
- install BeautifulSoup4
pip install beautifulsoup4- create the file name sample.py
- copy the sample code from the wikipedia
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))- above code is same as the below one.
response = urlopen('https://en.wikipedia.org/wiki/Main_Page')
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))- on your console, try
python sample.py- you will see the result like screenshot below
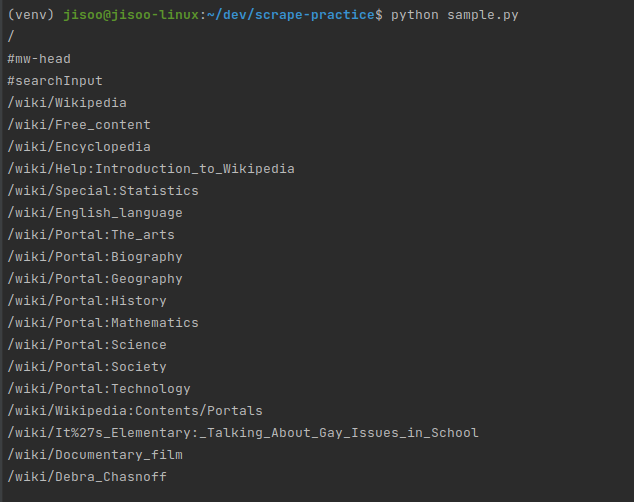
- now you are ready to do some scrape with this basic code.
3. try what you want to scrape.
- I will try with “premier league standings”.
- https://www.premierleague.com/tables
- hit f12 to open up the developer tools
- go to Elements tab
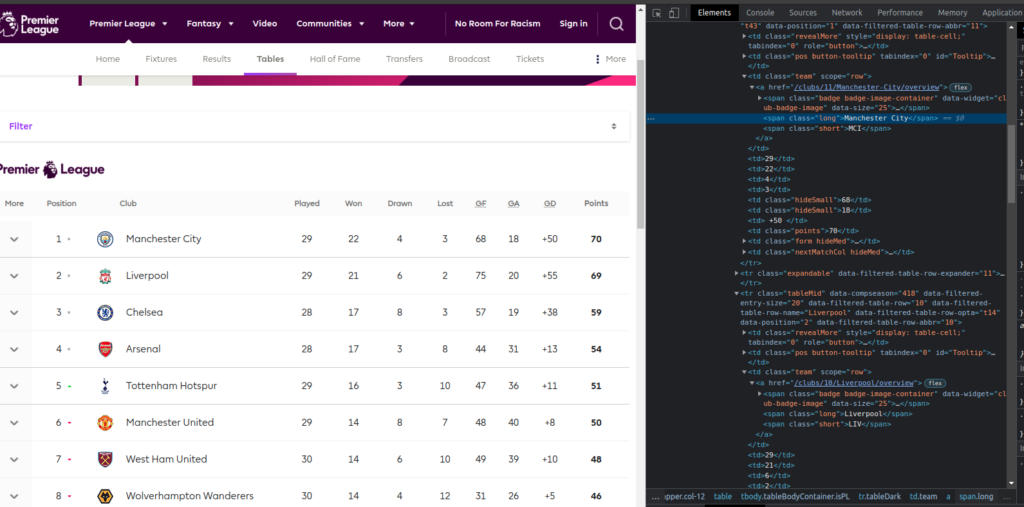
- what I want is just the texts.
- I will just get club names here.
- I will use css selectors in this sample.
- https://www.crummy.com/software/BeautifulSoup/bs4/doc/#css-selectors
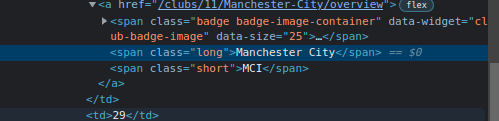
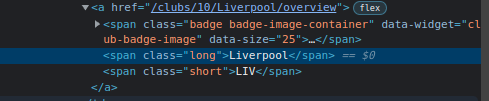
- if you see the html of the club names, there are the same format.
<span class="long">- create new file. in my case, I named scrape_pl.py
- you can copy the content from the sample and replace necessary things like below code.
- or you can copy the code below
from bs4 import BeautifulSoup
from urllib.request import urlopen
response = urlopen('https://www.premierleague.com/tables')
soup = BeautifulSoup(response, 'html.parser')
i = 1
for anchor in soup.select('span.long'):
print(str(i) + ":" + anchor.get_text())
i = i + 1- run the file by typing below on console
python scrape_pl.py- you will see the result like below screenshot
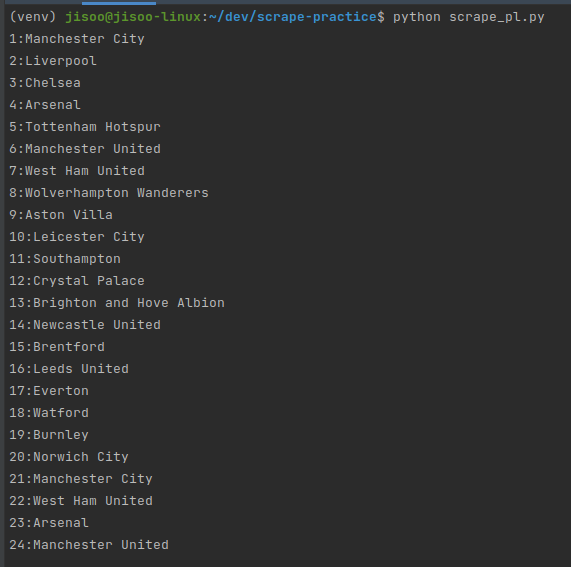
- you might found out there are more than 20 that we didn’t expected.
- that is because there are more on PL2 and U18.
- So, what should we do?
- we need to find the tag or other ways to specify as possible as we can.
- but in this case, they have almost same format.
- so, I will limit the for loop only up to 20 for this.
response = urlopen('https://www.premierleague.com/tables')
soup = BeautifulSoup(response, 'html.parser')
i = 1
l = 21
for anchor in soup.select('span.long'):
print(str(i) + ":" + anchor.get_text())
i = i + 1
if i == l:
break4. save the scraped data as txt file.
- add and edit some code from the above like below.
response = urlopen('https://www.premierleague.com/tables')
soup = BeautifulSoup(response, 'html.parser')
i = 1
l = 22
f = open("pl_standings.txt", 'w')
for anchor in soup.select('span.long'):
data = str(i) + ":" + anchor.get_text() + "\n"
i = i + 1
if i == l:
break
f.write(data)
f.close()- I didn’t add the exact path to test, and I guess it creates the file on the same root.
- if you run the file again, you will see the created txt file.
- some reason, if l = 21, it gives only up to 19th place. so I changed to 22.
- not sure what’s the issue.
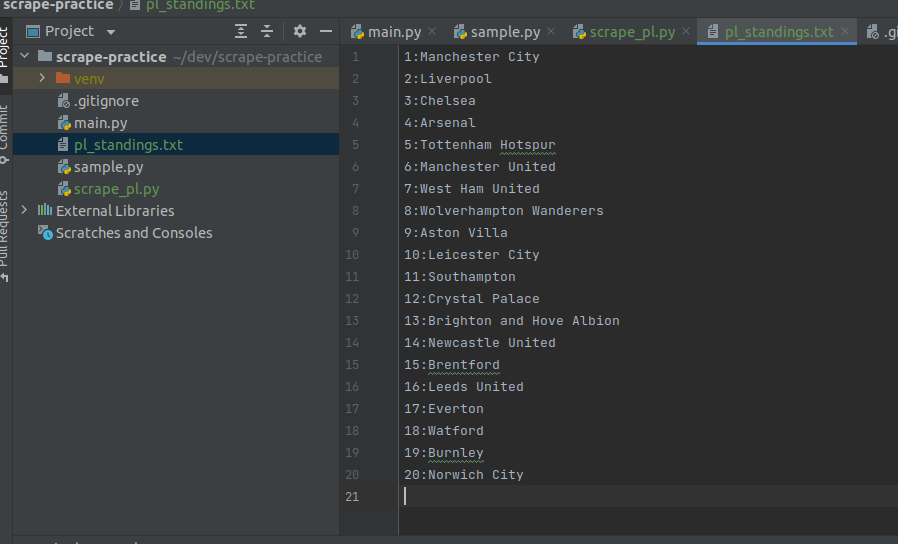
done for this post
